搜索:更好、更快、更小¶
这是我们如何设法完全重建客户端搜索的故事, 提供更好的用户体验,同时使其更快 同时变小。
MkDocs的材料搜索是迄今为止最好、最受欢迎的搜索之一 资产:[多语言],[离线功能],最重要的是:全部 客户端_。它提供了一种解决方案,可以增强文档用户的能力 立即找到他们正在寻找的东西,而不必担心管理问题 额外的服务器。然而即使已经进行了几次迭代, 还有一些改进的空间,这就是我们重建搜索的原因 插件和集成从头开始。这篇文章对 新搜索的内部结构,为什么它比以前强大得多 版本,以及即将到来的内容。
下一节将讨论当前搜索的架构和问题 实施。如果您想立即了解新内容,请跳到 [紧接着的部分][有什么新消息]。
结构¶
MkDocs的材料使用lunr和[lunr语言]来实现 其客户端搜索功能。加载文档页面时 JavaScript可用,搜索索引由 [内置搜索插件]在构建过程中被请求 服务器:
const index$ = document.forms.namedItem("search")
? __search?.index || requestJSON<SearchIndex>(
new URL("search/search_index.json", config.base)
)
: NEVER
搜索索引¶
搜索索引包括所有页面的精简版本。让我们采取一个 查看一个示例,以准确理解搜索索引包含的内容 原始Markdown文件:
展开以检查示例
# Example
## Text
It's very easy to make some words **bold** and other words *italic*
with Markdown. You can even add [links](#), or even `code`:
```
if (isAwesome) {
return true
}
```
## Lists
Sometimes you want numbered lists:
1. One
2. Two
3. Three
Sometimes you want bullet points:
* Start a line with a star
* Profit!
{
"config": {
"indexing": "full",
"lang": [
"en"
],
"min_search_length": 3,
"prebuild_index": false,
"separator": "[\\s\\-]+"
},
"docs": [
{
"location": "page/",
"title": "Example",
"text": "Example Text It's very easy to make some words bold and other words italic with Markdown. You can even add links , or even code : if (isAwesome) { return true } Lists Sometimes you want numbered lists: One Two Three Sometimes you want bullet points: Start a line with a star Profit!"
},
{
"location": "page/#example",
"title": "Example",
"text": ""
},
{
"location": "page/#text",
"title": "Text",
"text": "It's very easy to make some words bold and other words italic with Markdown. You can even add links , or even code : if (isAwesome) { return true }"
},
{
"location": "page/#lists",
"title": "Lists",
"text": "Sometimes you want numbered lists: One Two Three Sometimes you want bullet points: Start a line with a star Profit!"
}
]
}
如果我们检查搜索索引,我们会立即看到几个问题:
-
所有内容都包含两次: 搜索索引包含一个条目 包含页面的全部内容,每个部分对应一个条目 页面,即每个块前面都有一个标题或副标题。这 显著地影响了搜索索引的大小。
-
所有结构均已丢失: 构建搜索索引时,所有结构 从内容中剥离HTML标签和属性等信息。 虽然这种方法适用于段落和内联格式,但它 对于列表和代码块来说可能是有问题的。摘录:
-
Context: 对于一个未经训练的眼睛来说,结果可能看起来像胡言乱语,比如 目前还不清楚什么是文本,什么是代码。 此外,目前尚不清楚“列表”是否是合并后的标题 前面有代码块,后面有段落。
-
Punctuation: 内联元素,如紧随其后的链接 标点符号之间用空格隔开(参见 摘录)。这是因为所有提取的文本都用空格连接 在构建搜索索引的过程中。
-
不难看出,实施一个好的 主题作者的搜索体验,这就是为什么MkDocs材料(最多 现在)做了一些[猴子补丁],以便能够渲染得稍微多一些 有意义的搜索预览。
搜索工作人员¶
实际的搜索功能是作为web worker的一部分实现的1, 其创建和管理lunr搜索索引。当搜索被初始化时, 采取以下步骤:
-
将部分与页面链接: 解析搜索索引,每个 该部分链接到其父页面。父页面本身为_not indexed_,因为它会导致重复的结果,所以只有部分 留下来。链接是必要的,因为搜索结果是按页面分组的。
-
符号化: 每个部分的“title”和“text”值被拆分 使用中配置的[分隔符][分隔符]将令牌转换为
mkdocs.yml。标记化本身是通过以下方式进行的 [lunr的默认标记器][默认标记器],这不允许 前置或跨越多个字符的分隔符。为什么这很重要,很重要?我们稍后会看到我们还有多少 可以使用能够用以下方式分隔字符串的标记器来实现 向前看。
-
索引: 最后一步,对每个部分进行索引。查询时 如果搜索查询包括步骤2返回的令牌之一。, 该部分被视为搜索结果的一部分,并传递给 主线。
现在,这基本上就是搜索工作者的工作方式。当然,有一点 涉及更多的魔法,例如,搜索结果被[后处理]和[重新缩放]到 解释了lunr的一些缺点,但总的来说,数据就是这样得到的 进入和退出索引。
搜索预览¶
用户应该能够快速扫描和评估搜索的相关性 在给定的上下文中产生结果,这就是为什么要用突出显示的简洁摘要 搜索词的出现是大搜索的重要组成部分 经验。
这就是当前搜索预览生成不足的地方,因为一些 搜索预览似乎不包括任何搜索的出现 条款。这是由于搜索预览[在 最多320个字符][截断],如下图所示:
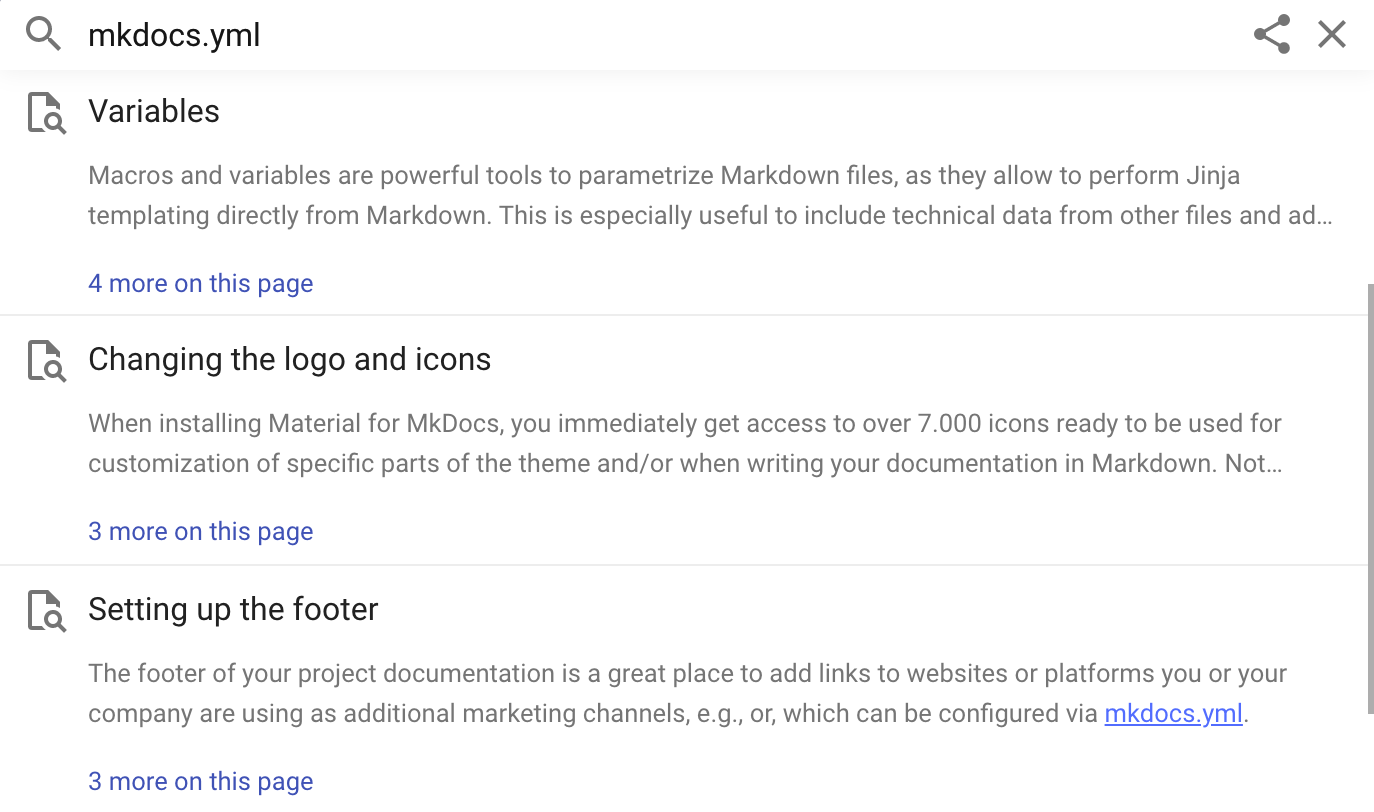
前两个结果看起来并不相关,因为它们似乎并不相关 包括用户刚刚搜索的查询字符串。然而,他们确实如此。
这个问题的更好解决方案已经在路线图上存在了很长时间 时间,但为了一劳永逸地解决这个问题,需要考虑几个因素 仔细考虑:
-
Word boundaries: 静态站点生成器生成的一些主题6 通过在事件旁边左右展开文本来进行搜索预览, 当已经消耗了足够多的单词时,在空白字符处停止。一 预览可能看起来像这样:
虽然这可能适用于使用空格作为分隔符的语言 在单词之间,它分解为日语或汉语等语言5, 因为它们具有非空白的单词边界,并使用专用的分词器 将字符串拆分为标记。
-
Context-awareness: 虽然空白并不适用于所有语言, 有人可能会说,这可能是一个足够好的解决方案。不幸的是,这 对于代码块不一定是正确的,因为删除空格可能会 改变某些语言的含义。
-
Structure: 保存结构信息不是必须的,但 显然有利于构建更有意义的搜索预览,从而允许 以便快速评估相关性。如果单词出现是代码的一部分 块,它应该被呈现为代码块。
有什么新鲜事吗?¶
在我们对问题空间有了扎实的理解之后,在我们潜水之前 深入我们新的搜索实现的内部,看看是哪一个 它已经解决的问题,快速概述哪些功能和改进 它带来了:
- Better: 支持[丰富的搜索预览],保留结构 代码块、内联代码和列表的信息,因此它们被呈现 按原样,以及[前瞻标记化]、[更准确的突出显示],以及 改进了typeahead的稳定性。此外,还有[稍微好一点的用户体验]。
- Faster and smaller: up的搜索索引大小显著减小 由于提取和施工技术的改进,这一比例降至48%,导致 搜索体验速度提高了95%,这对 大型文档项目。
[rich search previews]: [lookahead tokenization]: [more accurate highlighting]:
丰富的搜索预览¶
当我们从头开始重建搜索插件时,我们重新设计了 用于内联保存代码块结构信息的搜索索引 代码,以及无序和有序列表。使用以下示例 [搜索索引]部分,如下所示:
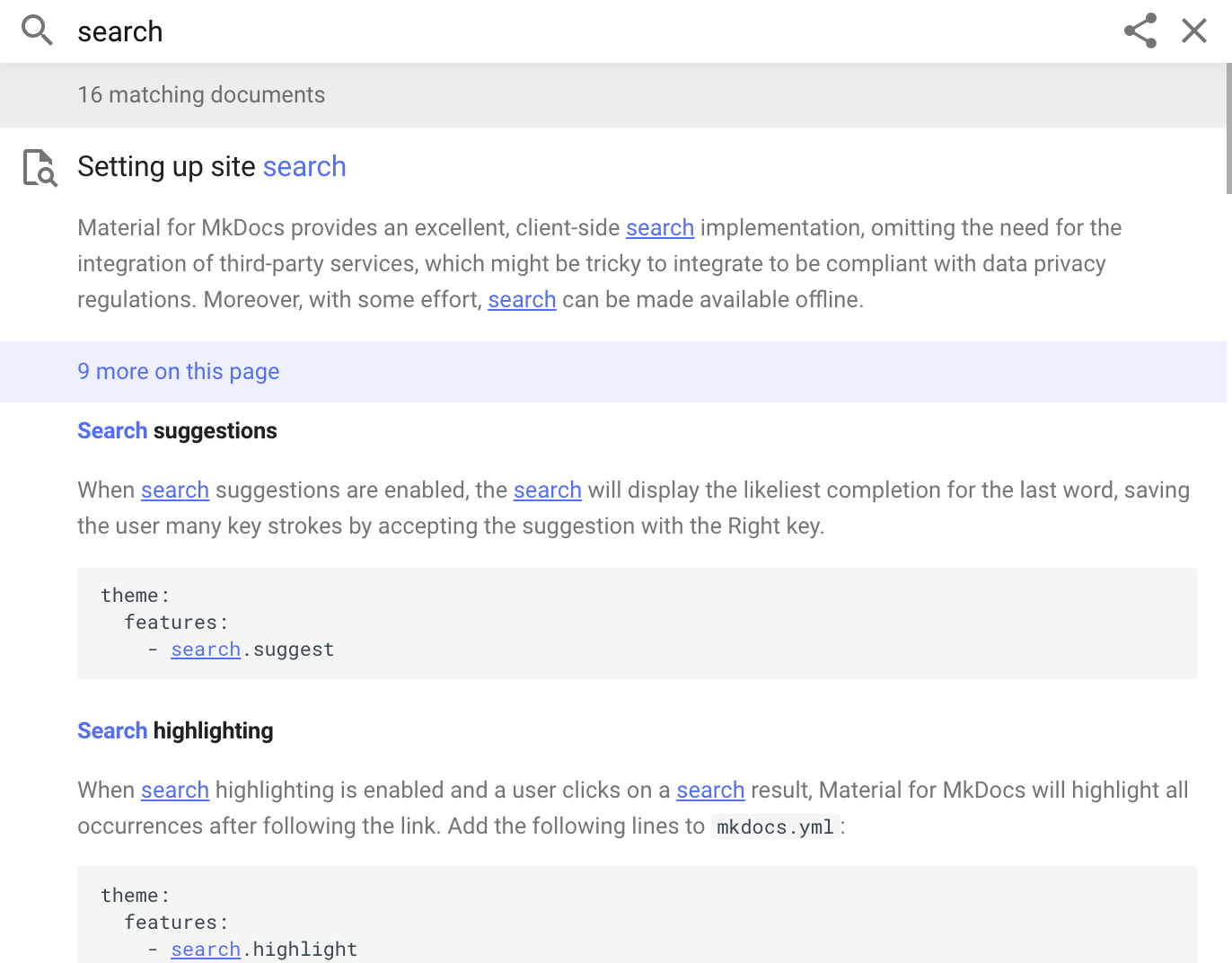
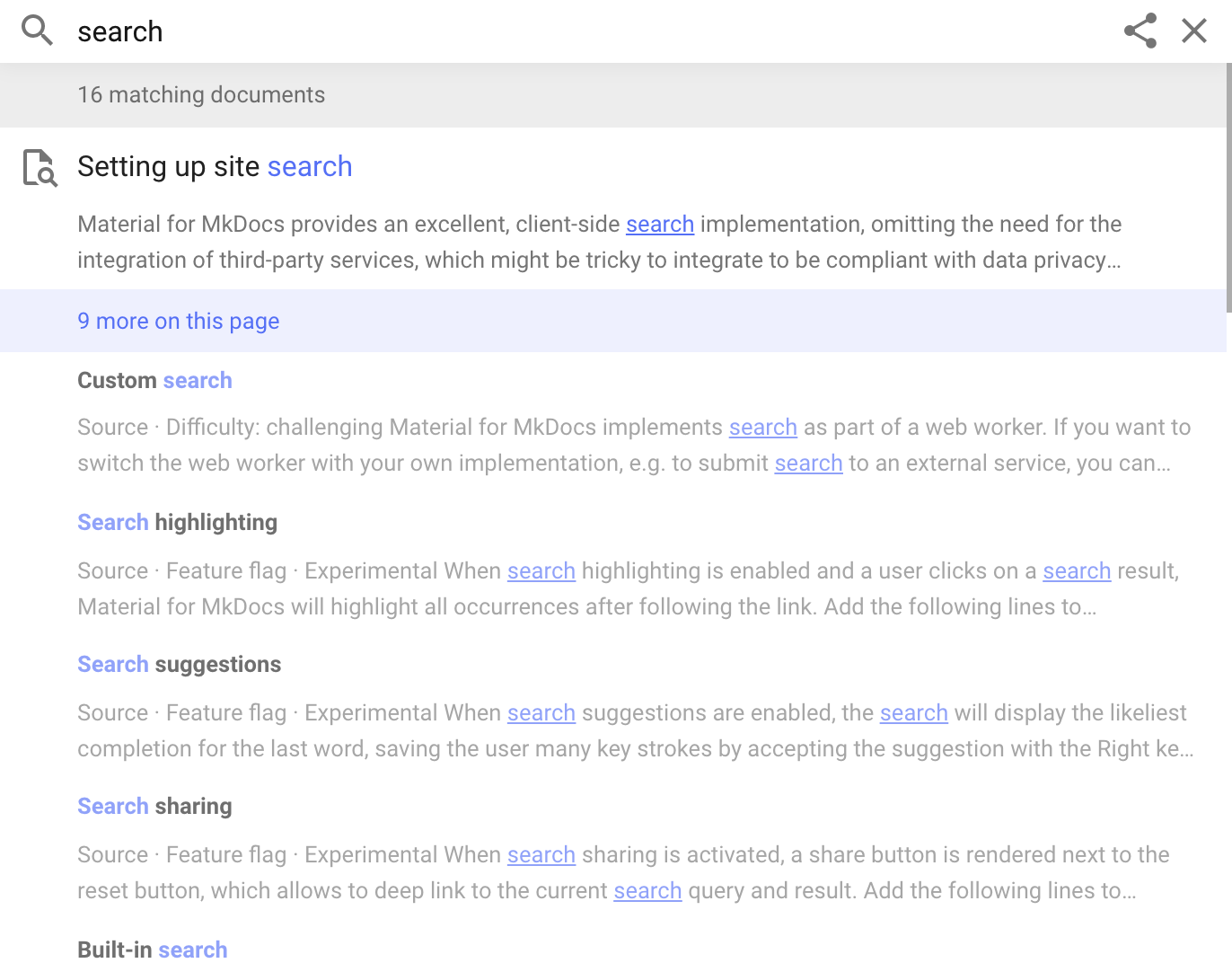
现在,代码块是搜索预览的一级公民,甚至 内联代码格式得以保留。让我们来看看新的结构 搜索索引以了解原因:
展开以检查搜索索引
{
...
"docs": [
{
"location": "page/",
"title": "Example",
"text": ""
},
{
"location": "page/#text",
"title": "Text",
"text": "<p>It's very easy to make some words bold and other words italic with Markdown. You can even add links, or even <code>code</code>:</p> <pre><code>if (isAwesome){\n return true\n}\n</code></pre>"
},
{
"location": "page/#lists",
"title": "Lists",
"text": "<p>Sometimes you want numbered lists:</p> <ol> <li>One</li> <li>Two</li> <li>Three</li> </ol> <p>Sometimes you want bullet points:</p> <ul> <li>Start a line with a star</li> <li>Profit!</li> </ul>"
}
]
}
{
...
"docs": [
{
"location": "page/",
"title": "Example",
"text": "Example Text It's very easy to make some words bold and other words italic with Markdown. You can even add links , or even code : if (isAwesome) { return true } Lists Sometimes you want numbered lists: One Two Three Sometimes you want bullet points: Start a line with a star Profit!"
},
{
"location": "page/#example",
"title": "Example",
"text": ""
},
{
"location": "page/#text",
"title": "Text",
"text": "It's very easy to make some words bold and other words italic with Markdown. You can even add links , or even code : if (isAwesome) { return true }"
},
{
"location": "page/#lists",
"title": "Lists",
"text": "Sometimes you want numbered lists: One Two Three Sometimes you want bullet points: Start a line with a star Profit!"
}
]
}
如果我们再次检查搜索索引,我们可以看到情况是如何改善的:
-
内容只包含一次: 搜索索引不包括 页面内容两次,因为只有页面的部分是 搜索索引。这导致大小显著减小,字节数减少 传输和较小的搜索索引。
-
部分结构得以保留: 搜索索引的每个部分包括 HTML的一个子集,提供必要的结构,以允许更多 复杂的搜索预览。让我们回顾一下之前的例子 看看摘录:
标点符号问题消失了,因为没有插入额外的空格 保留的标记会产生额外的上下文,以便进行扫描搜索 结果更有效。
接下来是流程的下一步:tokenization。
Tokenizer展望¶
lunr的[默认标记器]使用正则表达式来分割给定的 通过将每个字符与[分隔符][分隔符]进行匹配,得到字符串 在mkdocs.yml中定义。这不允许基于更复杂的分离器 前瞻性或多个字符。
幸运的是,我们的新搜索实现提供了一个高级标记器 它没有这些缺点,支持更复杂的正则表达式 表达。因此,MkDocs的材料只是更改了自己的分隔符 配置为以下值:
而第一部分直到第一个“|”包含一个单一控件列表 字符串应拆分的字符,以下三个部分 解释正则表达式的其余部分。2
案例变更¶
许多编程语言使用“PascalCase”或“camelCase”命名约定。 当用户搜索“案例”一词时,很自然地会期望 `PascalCase和camelCase将出现。通过将以下比赛组添加到 分离器,现在可以轻松实现:
这个正则表达式是负前瞻('\b'。, 不是单词边界)和正向前瞻([a-Z][a-Z],即大写 字符后跟小写字符),并具有以下行为:
PascalCase:octicons-arrow-right-24:Pascal,CasecamelCase:octicons-arrow-right-24:camel,CaseUPPERCASE:octicons-arrow-right-24:UPPERCASE
正在搜索:octicons-search-24:searchHighlight 现在,我们将讨论“搜索突出显示”功能标志 这也表明,现在它甚至可以正确地用于搜索查询。3.
版本号¶
索引版本号是另一个可以用小程序解决的问题 向前看。通常,”。应被视为分隔词的分隔符,如搜索.突出显示。但是,在处拆分版本号。`会让他们 无法发现。因此,以下表达式:
这个正则表达式匹配一个。如果不是紧接着a 数字“\d”,使版本号可被发现。正在搜索 :octicons-search-24:7.2.6显示7.2.6发行说明。
HTML/XML tags¶
如果您的文档包含HTML/XML代码示例,您可能希望允许 用户可以查找特定的标签名称。不幸的是,“<”和“>”控件 字符在代码块中编码为<;以及>;.现在,添加 分隔符的以下表达式允许这样做:
我们才刚刚开始触及新可能性的表面 代币化者展望未来。如果你发现了其他有用的表达方式,你 受邀在评论区分享。
准确突出显示¶
突出显示是搜索过程的最后一步,涉及 突出显示给定搜索结果中出现的所有搜索词。对于a 长时间以来,突出显示是通过动态生成来实现的 [正则表达式]。4.
这种方法在日语或日语等非空白语言中存在一些问题 中文5,因为它只有在突出显示的术语位于单词边界时才有效。 然而,亚洲语言使用[专用分段器]进行标记 不能用正则表达式建模。
现在,作为[新标记化方法]的直接结果,我们的新搜索 实现使用标记位置来突出显示__,使其与 强大的代币化:
-
单词边界: 由于新的荧光笔使用标记位置,单词 边界等于令牌边界。这意味着更复杂的情况 标记化(例如,[案例更改]、[版本号]、[HTML/XML标签]), 现在都准确地突出显示了。
-
情境感知: 由于新的搜索索引保留了一些 原始文档的结构信息,章节的内容 现在被划分为单独的内容块——段落、代码块和 列表。
现在,只有实际包含以下内容之一的内容块 考虑将搜索词包含在搜索预览中。如果a 该术语仅出现在代码块中,它是被渲染的代码块, 例如,请查看以下结果 :octicons-search-24: twitter.
[new tokenization approach]:
基准¶
我们进行了两个基准测试——一个是MkDocs的材料文档 它本身,以及一个拥有大量Markdown文件的语料库,其中包含超过 800000字——大多数文档项目可能永远不会达到这个规模 范围:
| Before | Now | Relative | |
|---|---|---|---|
| Material for MkDocs | |||
| Index size | 573 kB | 335 kB | –42% |
Index size (gzip) | 105 kB | 78 kB | –27% |
| Indexing time7 | 265 ms | 177 ms | –34% |
| KJV Markdown8 | |||
| Index size | 8.2 MB | 4.4 MB | –47% |
Index size (gzip) | 2.3 MB | 1.2 MB | –48% |
| Indexing time | 2,700 ms | 1,390 ms | –48% |
Benchmark results
结果表明,索引时间,即设置所需的时间 加载页面时的搜索下降了48%,这意味着 新搜索速度高达95%。这是一个显著的改进, 尤其适用于大型文档项目。
使用新的客户端搜索,1、3听起来可能仍然很长时间 与[即时加载]一起,仅在初始位置创建搜索索引 页面加载。导航时,搜索索引会跨页面保留,因此 费用只需支付一次。
用户界面¶
此外,还进行了一些小的改进,最突出的是 __此页面上的更多结果__按钮,该按钮现在位于搜索的顶部 打开时的结果列表。这使用户能够更多地跳出列表 迅速地。
接下来是什么?¶
我们新的搜索实现是对Material for MkDocs的一大改进。它 解决了一些需要多年解决的长期问题。然而, 这只是一个搜索体验的开始,它会变得更好 更好。接下来:
-
上下文感知搜索摘要: 目前,前两个匹配 内容块被呈现为搜索预览。随着新的代币化 技术,我们为更复杂的缩短和 总结方法,我们接下来要解决。
-
用户界面改进: 因为我们现在完全控制了 搜索插件,我们现在可以添加有意义的元数据来提供更多的上下文和 更好的体验。我们将在未来探索其中的一些路径。
如果你已经走到了这一步,感谢你对材料的时间和兴趣 对于MkDocs!这是我决定写的第一篇博客文章 简短的[推特调查]让我关注。欢迎您发表评论 分享您使用新搜索实现的经验。
-
之前<!--md:版本5.0.0→,在主目录中进行搜索 线程锁定了浏览器,使其无法使用。这个问题是 第一次报告于904年,经过一番反复,修复并发布于
version 5.0.0. ↩ -
一个有趣的事实:搜索的[分隔符][分隔符][默认值] 正如它所暗示的那样,插件为“[\s-]+”总是有点令人恼火 多个字符可以被视为分隔符。然而
+这是完全无关的,因为正则表达式组涉及 从未支持多个字符 [lunr的默认标记器][默认标记器]。 ↩ -
以前,由于以下原因,搜索查询没有正确标记 lunr处理通配符,因为它禁用了搜索词的管道 包含通配符。为了提供良好的提前打字体验, MkDocs的材料在每个搜索词的末尾添加通配符,而不是 明确地以“+”或“-”开头,有效地禁用了标记化。 ↩
-
使用
mkdocs.yml中定义的分隔符,正则表达式为 构建了一个试图模仿标记器的模型。例如 搜索查询“搜索高亮”被转化为相当繁琐 正则表达式“(^|)(search | highlight)”,仅匹配 在单词边界。 ↩ -
在撰写本文时,Just the Docs和Docusaurus使用了这种方法 用于生成搜索预览。请注意,后者还与 Algolia是一个完全托管的基于服务器的解决方案。 ↩
-
十次不同运行中的最小值。 ↩
-
我们不可知地使用KJV Markdown作为测试工具,以了解如何 MkDocs的材料在大型语料库上表现良好,因为它是一个非常大的集合 超过80万字的Markdown文件。 ↩